Advanced usage
As well as the general workflow described in the previous pages, FAST can be flexibly adapted to support more specific analytical tasks.
Non-standard workflows
Although FAST contains all the essential tools for a complete image to track workflow, some users may wish to extend and adjust portions of this workflow. For example, you may find that a different segmentation algorithm is more effective at analysing your data than FAST's inbuilt segmentation module, or that you need to extract a custom feature from your dataset for use during tracking. The modular design of FAST is intended to support these users.
Please note that the majority of these advanced features are only available if you are running the Matlab-based version of FAST. These tools generally require small tweaks to FAST's source code, which is only possible in the Matlab-based implementation.
Use of external segmentations
The segmentation module is designed to be adaptable to many different datasets. However, there are many situations where other approaches (such as level sets, or machine-learning based approaches) may be more successful. If you find this to be the case, but still wish to make use of FAST's tracking and data display capabilities, these externally generated segmentations can be used in place of the output of the segmentation module.
Scenario 1: FAST's data importer can be used
FAST expects raw and segmented images to be provided in a specific format. If you are able to use FAST's integrated data importer, the raw images will be taken care of automatically. In this case, you only need to save your segmented images in a new 'Segmentations' folder, located in your root directory. In this folder, each individual segmentation frame should be saved as 'Frame_XXXX.tif', where XXXX indicates the corresponding timepoint indexed from 0. For example, the segmentation for timepoint 5 should be saved as 'Frame_0004.tif'. If you are able to open your series of segmentation images as a stack, you can quickly achieve this within FIJI by saving this stack through File → Save As → Image Sequence…, then typing 'Frame_' into the 'Name:' field of the dialogue box that appears.
Scenario 2: FAST's data importer cannot be used
If for some reason you are not able to use the integrated data import method in scenario 1, you will also need to provide FAST with metadata about your imaging dataset. To do this, specify the following fields of the metaStore structure:
metaStore.maxX = 764; % Number of columns in your images (pixels) metaStore.maxY = 572; % Number of rows in your images (pixels) metaStore.maxT = 50; % Number of timepoints in your dataset metaStore.dt = 0.2; % Time between adjacent timepoints (physical units) metaStore.dx = 12.9; % Edge size of a single pixel (physical units) metaStore.dy = 12.9; % Edge size of a single pixel (physical units) (should be equal to dx)
This structure should now be saved under the name 'Metadata.mat' in your root directory:
save(fullfile('your/root/directory','Metadata.mat'),'metaStore')
You should also specify and save the following options in the segmentParams structure:
segmentParams.segmentChan = 1; % Index of the channel segmentations were performed on (will be used for data display purposes later) segmentParams.noChannels = 3; % Number of channels in your dataset save(fullfile('your/root/directory','SegmentationSettings.mat'),'segmentParams')
If using the stand-alone version of FAST, functions that can write .mat files from other languages (such as R's writeMat function) should be used to perform this step.
You will also need to provide FAST with the raw images from your dataset. This can be performed using FIJI in a similar way to the the segmentations, but each file ('Frame_0000.tif' etc.) should be saved in a folder named 'Channel_N', where N indicates the index of the channel that image represents. For example, the 5th image of the 2nd channel in your dataset should be saved under 'root/Channel_2/Frame_004.tif'.
Custom feature extraction
If there is a novel feature you wish to analyse but which is not natively provided by the feature extraction module, it may be possible to add it to the feature extraction process by writing a new 'customFeats.m' function. This is a flexible piece of code that can be used for many purposes, and takes the following general form:
- customFeatsTemplate.m
function feats = customFeats(inSeg,inChans,pxSize) %CUSTOMFEATS can be customised to allow extraction of custom features from %your dataset in the feature extraction module. % % INPUTS: % -inSeg: Image containing the segmentation mask for the current % object % -inChans: Cell array containing the images of the cell in each % imaging channel % Note: Input segmentation and channel images have been cut from the % original (full) images based on the bounding box of the % segmentation. Absolute positions in the reference frame % therefore can't be extracted using this script (although % relative positions can be). % -pxSize: Physical size of pixels in the image, in dataset specific % dimensions. % % OUTPUTS: % -feats: Vector of extracted feature values. If inSeg and inChans % are empty, should return a vector of zeros of the same size as % the output feature vector if these inputs were not empty - this % is used to initialise storage in the feature extraction engine. % % Author: Oliver J. Meacock (c) 2020 %% Feature extraction code goes here. %Swap dimensions of feature vector (if needed) if size(feats,1) == 1 && size(feats,2) > 1 feats = feats'; end
This function provides you with images of each object in each available channel, along with the associated segmented mask. Following your custom-written analysis, the function should return a feature vector containing numerical values for each feature associated with this object. These will be stored in the spareFeatX fields of the trackableData structure stored in 'CellFeatures.mat', and can be accessed directly for use during tracking and division detection. To use them, simply tick the 'Spare feature X' checkboxes that become available within the 'features for inclusion' box at the top of each module's window. Note that the tracking and feature detection modules support a maximum of four additional features on top of those available by default.
As discussed below, FAST may need to be provided with additional details about any novel features. Please read the linked section to decided if this applies to you.
Once you have finished writing your customFeats function, save it to the root directory of your analysis. FAST will now automatically use it to extract the specified features from each detected object in each frame.
As an example, the following cellFeats function was written to measure the curvature of cells as a feature:
function feats = customFeats(inSeg,inChans,pxSize) %CUSTOMFEATS can be customised to allow extraction of custom features from %your dataset in the feature extraction module. % % INPUTS: % -inSeg: Image containing the segmentation mask for the current % object % -inChans: Cell array containing the images of the cell in each % imaging channel % Note: Input segmentation and channel images have been cut from the % original (full) images based on the bounding box of the % segmentation. Absolute positions in the reference frame % therefore can't be extracted using this script (although % relative positions can be). % -pxSize: Physical size of pixels in the image, in dataset specific % dimensions. % % OUTPUTS: % -feats: Vector of extracted feature values. If inSeg and inChans % are empty, should return a vector of zeros of the same size as % the output feature vector if these inputs were not empty - this % is used to initialise storage in the feature extraction engine. % % Author: Oliver J. Meacock (c) 2020 %Need to specify the case where both inputs are empty (special case used to %initialise storage properly) if isempty(inSeg) && isempty(inChans) feats = 0; else %Skeletonise segmentation to generate cell backbone backbone = bwskel(logical(inSeg),'MinBranchLength',8); %If skeleton is very small, implies cell is close to circular. %Backbone curvature is poorly defined in this case, so set to NaN. if sum(backbone(:)) < 10 feats = NaN; else %Run circular fitting algorithm. Function available here: https://uk.mathworks.com/matlabcentral/fileexchange/22643-circle-fit-pratt-method [y,x] = ind2sub(size(inSeg),find(backbone)); circParams = CircleFitByPratt([x,y]); feats = 1/(circParams(3)*pxSize); end end %Swap dimensions of feature vector (if needed) if size(feats,1) == 1 && size(feats,2) > 1 feats = feats'; end
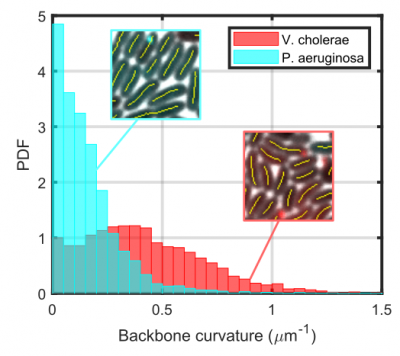
By applying this to a mixture of V. cholerae and P. aeruginosa cells (separated into different populations based on fluorescence with the post-processing toolbox), the characteristic curvature of Vibrio cells compared to Pseudomonas cells can readily be quantified:
Import of non-segmentable objects
Depending on the application, you may be unable to detect objects using the segmentation module. In this example, we will look at topological defects, positions in liquid crystals where the local orientation field changes instantaneously. You can find further details about topological defects here, but one aspect of them is that each is associated with an invariant charge. This package contains Matlab code allowing extraction of the positions, orientations and charges of all defects in a timelapse dataset.
Because defect charge is constant over time, it is a very useful feature for improving defect tracking. In the following, we will see how we can format defect position, orientation and charge data so they can be used by downstream modules.
To make the defect feature data available to the tracking module, we first need to store the data in a form that the tracking module will be able to read. The format in question is described in the documentation for the feature extraction module, and forms the basis of the CellFeatures.mat file which that module saves.
Defect data is stored as separate fields in the trackableData structure:
%Loop over timepoints for t = 1:size(posDefectOrientationStore,1) %Each row of pDposition{t} and nDposition{t} contains the (x,y) coordinates of a single defect trackableData.Centroid{t} = [pDposition{t};nDposition{t}]; %Similarly for defect orientation: trackableData.Orientation{t} = [pDorientation{t};nDorientation{t}]; %SpareFeat1 contains the defect charge information. Additional features MUST be called SpareFeat1, SpareFeat2 etc. in the trackable data structure to be read by the tracking module trackableData.SpareFeat1{t} = [ones(size(positiveDefectStore{t}));-ones(size(negativeDefectStore{t}))]; end
We also need to provide some additional information to the featSettings structure, since we are bypassing the metadata input stages available in the data import section:
featSettings.noChannels = 1; %Number of input channels featSettings.MeanInc = []; %Channel indices of pixel averages to use featSettings.StdInc = []; %Channel indices of pixel standard deviations to use featSettings.dt = 2; %Size of timestep between frames of dataset featSettings.pixSize = 0.0720635; %Side length of pixel (in um) featSettings.maxX = 0.0720635*2752; %Width of image (in um) featSettings.maxY = 0.0720635*2208; %Height of image (in um) maxT = 600; %Maximum frame save('D:\DNAseI assays\DNAse-\CellFeatures.mat','trackableData','featSettings','maxT');
Once feature import is complete, the first spare feature checkbox is again made available when the tracking module is initialised:
This corresponds to the defect charge data, which we saved as the trackableData.SpareFeat1 field. This can now be used like any other feature during tracking.
Telling FAST about novel features
Whether you add features through the customFeats.m script or create a new feature structure from scratch, FAST needs to be told some information about the properties of any features not included in its default setup.
Informing the tracking module
Although the tracking module is able to extract most of the relevant information of each feature directly, the general form each feature takes still needs to be defined. For example, is the new feature linear (like object length) or circular (like object orientation)? These pieces of information are defined in the 'prepareTrackStruct.m' file, located in the 'Tracking' directory of the FAST code directory.
Upon opening this file and scrolling through it, you will come across the default settings for each new feature:
if trackSettings.SpareFeat1 == 1 featureStruct.('SpareFeat1').('Locations') = 1; featureStruct.SpareFeat1.('StatsType') = 'Linear'; end
For the majority of features (including the cell curvature and topological defect charge examples discussed above), the default settings are already correct, so we do not need to make any modifications. In general however, the following fields of the featureStruct.SpareFeat1 settings structure may need to be modified:
- Locations defines the columns in trackableData that should be included as separate features. For example, each cell in trackableData.Centroid contains an Nx2 matrix of values, with the first column indicating the x-coordinate of the N objects and the second column the y-coordinate. As checking the Position box in the tracking module indicates that you wish to include both x and y coordinate data as features, featureStruct.Centroid.Locations is set as [1,2].
- StatsType defines if your feature is circular or linear.
- Range only needs to be defined if StatsType is set as circular, and sets the 'seams' of the wrapped number line. For example, the object orientation phi transitions smoothly from -90° to 90°; featureStruct.Orientation.Range is therefore set as [-90 90].
Informing the division detection module
If you also want to use additional features during division tracking, you will also need to edit the 'prepareDivStruct.m' file, located in the 'Division Tracking' directory of the FAST code directory. Scrolling though this file, you will find the default settings for the new feature:
if divSettings.SpareFeat1 == 1 featureStruct.('sparefeat1').('Locations') = 1; featureStruct.sparefeat1.('divArguments') = {}; featureStruct.sparefeat1.('postDivScale1') = @(x) x; featureStruct.sparefeat1.('postDivScale2') = @(x) x; featureStruct.sparefeat1.('StatsType') = 'Linear'; end
As well as the previously described Locations and StatsType fields, several additional settings need to be set in this structure. These define the initial model for where daughters will appear in feature space when their mother divides:
- divArguments is a cell array, containing the names of any features of the mother needed to predict the value of this feature for the daughters.
- postDivScale1 contains a function handle, defining the predicted value of the feature for the first daughter. The features defined in divArguments can be used to make this prediction.
- postDivScale2 contains a function handle, defining the predicted value of the feature for the second daughter.
For example, the x-coordinates $x_{d1}$ and $x_{d2}$ of two daughter cells can be predicted using the equations
$x_{d1} = x_m + \frac{l_m}{4}\cos(\phi_m),$
$x_{d2} = x_m - \frac{l_m}{4}\cos(\phi_m),$
where $x_m$, $l_m$ and $\phi_m$ are the x-coordinate, length and orientation of the mother cell, respectively. This relationship between the features of the mother and those of the daughters are defined using the code
featureStruct.('x').('Locations') = 1; featureStruct.x.('divArguments') = {'x','phi','majorLen'}; featureStruct.x.('postDivScale1') = @(x) x(1) + cosd(-x(2))*x(3)*0.25; featureStruct.x.('postDivScale2') = @(x) x(1) - cosd(-x(2))*x(3)*0.25; featureStruct.x.('StatsType') = 'Linear';
This initial model is then refined during model training in the division detection module.
Population and event labelling
Both the overlays and plotting modules support two types of user-defined data: track populations and track events:
- Populations can be used to split tracks into subsets with specific characteristics, e.g. splitting cell tracks into populations with different levels of fluorescence, or different sizes.
- Events can be used to define the time at which specific actions occur within a track, e.g. when a cell changes colour, or reverses its direction of movement.
Both of these types of data are added to the procTracks data structure based on the analytical requirements of the user.
The procTracks.population field should be set as an integer for each track, e.g.
procTracks(10).population = 1; procTracks(11).population = 2;
would set track 10 to be a member of population 1 and track 11 to be a member of population 2. Population labels should start at 1 and increase sequentially for each new population (e.g. for a 3 population dataset, the population labels should be 1, 2 and 3).
The procTracks.event field for each track should be a $t \times 1$ column vector, containing the event label for each timepoint. Each event vector should containin zeros for all timepoints without events and an integer label for all timepoints with events. For example,
eventLabel = zeros(size(procTracks(10).x)); eventLabel(15) = 1; eventLabel(21) = 2; procTracks(10).event = eventLabel;
would set track 10 to have a class 1 event occur at timepoint 15 and a class 2 event occur at timepoint 21.
Examples of scripts and functions implementing population and event labelling can be found in the post-processing toolbox.